Genetski algoritmi: suština, opis, primjeri, primjena
Ideja o genetskim algoritmima (GA) pojavila se prilično davno (1950–1975), ali su postali stvarni predmet proučavanja tek posljednjih desetljeća. D. Holland se smatrao pionirom u ovom području, koji je posudio mnogo genetike i prilagodio ga računalima. GA se široko koriste u sustavima umjetne inteligencije, neuronskim mrežama i problemima optimizacije.
Evolucijska potraga
Modeli genetskih algoritama nastali su na temelju evolucije u divljini i metodama slučajnog pretraživanja. U isto vrijeme, nasumično pretraživanje je implementacija najjednostavnije evolucijske funkcije - slučajnih mutacija i naknadnog odabira.
S matematičkog stajališta, evolucijsko pretraživanje znači ništa više od transformacije postojećeg konačnog skupa rješenja u novo. Funkcija odgovorna za ovaj proces je genetsko pretraživanje. Glavna razlika takvog algoritma od slučajnog pretraživanja je aktivna upotreba informacija prikupljenih tijekom ponavljanja (ponavljanja).
Zašto su nam potrebni genetski algoritmi
GA ima sljedeće ciljeve:
- objasniti mehanizme prilagodbe kako u prirodnom okruženju tako iu intelektualno-istraživačkom (umjetnom) sustavu;
- modeliranje evolucijskih funkcija i njihova primjena za učinkovito traženje rješenja različitih problema, uglavnom optimizacijskih.
U ovom trenutku, bit genetskih algoritama i njihove modificirane verzije mogu se nazvati traženjem učinkovitih rješenja, uzimajući u obzir kvalitetu rezultata. Drugim riječima, pronalaženje najbolje ravnoteže između performansi i preciznosti. To se događa zbog poznate paradigme "opstanka najsposobnijeg pojedinca" u neizvjesnim i nejasnim uvjetima.
Značajke GA
Navešćemo glavne razlike GA od većine drugih metoda pronalaženja optimalnog rješenja.
- raditi s parametrima zadatka, kodiranim na određeni način, a ne izravno s njima;
- potraga za rješenjem ne događa se specificiranjem početne aproksimacije, već skupom mogućih rješenja;
- koristeći samo objektivnu funkciju, bez pribjegavanja njezinim izvedenicama i modifikacijama;
- primjena probabilističkog pristupa analizi umjesto strogo determinističkog.
Kriteriji izvedbe
Genetski algoritmi izrađuju izračune na temelju dvaju uvjeta:
- Izvedite određeni broj iteracija.
- Kvaliteta pronađenog rješenja zadovoljava zahtjeve.
Ako je jedan od ovih uvjeta ispunjen, genetski algoritam će prestati s daljnjim iteracijama. Osim toga, korištenje GA u različitim regijama prostora rješenja omogućuje im da pronađu mnogo bolja nova rješenja koja imaju prikladnije vrijednosti ciljne funkcije.
Osnovna terminologija
Zbog činjenice da se GA temelji na genetici, većina terminologije odgovara tome. Svaki genetski algoritam djeluje na temelju početnih informacija. Skup početnih vrijednosti je populacija t t = {n 1 , n 2 , ..., n n }, gdje je n i = {r 1 , ..., r v }. Detaljnije ćemo ispitati:
- t je broj ponavljanja. t 1 , ..., t k - znači ponavljanje algoritma od broja 1 do k, a pri svakoj iteraciji stvara se nova populacija rješenja.
- n je veličina populacije P t .
- 1 , ..., п i - хромосома, особь, или организм. n 1 , ..., n i - kromosom, pojedinac ili organizam. Kromosom ili lanac je kodirana sekvenca gena, od kojih svaki ima sekvencijski broj. Treba imati na umu da kromosom može biti poseban slučaj pojedinca (organizma).
- rv su geni koji su dio kodiranog rješenja.
- Lokus je sekvencijski broj gena u kromosomu. Alel je genska vrijednost koja može biti i numerička i funkcionalna.
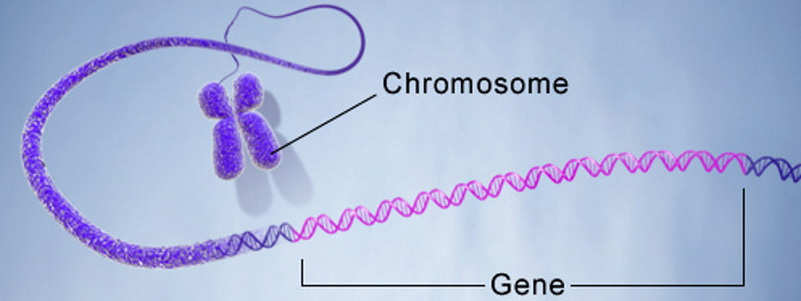
Što znači "kodiran" u kontekstu GA? Obično se svaka vrijednost kodira na temelju abecede. Najjednostavniji primjer je pretvorba brojeva iz decimalnog broja u binarni prikaz. Dakle, abeceda je predstavljena kao skup {0, 1}, a broj 157 10 će biti kodiran kromosomom 100111012, koji se sastoji od osam gena.
Roditelji i potomci
Roditelji su elementi odabrani u skladu s danim uvjetima. Na primjer, često je ovo stanje nesreća. Odabrani elementi zbog operacija križanja i mutacije stvaraju nove, koje se nazivaju potomci. Dakle, roditelji tijekom provedbe jedne iteracije genetskog algoritma stvaraju novu generaciju.
Konačno, evolucija u ovom kontekstu će biti izmjena generacija, od kojih se svaka nova razlikuje po skupu kromosoma radi bolje kondicije, odnosno, boljeg usklađivanja s navedenim uvjetima. Opća genetska pozadina u procesu evolucije naziva se genotip, a formiranje veze organizma s vanjskim okruženjem naziva se fenotip.
Funkcija fitnessa
Čarolija genetskog algoritma u fitnes funkciji. Svaki pojedinac ima svoju vrijednost koja se može naučiti kroz funkciju prilagodbe. Njegova je glavna zadaća procijeniti ove vrijednosti za različita alternativna rješenja i odabrati najbolje. Drugim riječima, najsposobniji.
U optimizacijskim problemima funkcija fitnessa naziva se target, u teoriji kontrole naziva se pogreška, u teoriji igara ona je funkcija vrijednosti i tako dalje. Što će točno biti predstavljeno kao funkcija prilagodbe ovisi o problemu koji treba riješiti.
Na kraju, može se zaključiti da genetski algoritmi analiziraju populaciju pojedinaca, organizama ili kromosoma, od kojih je svaki predstavljen kombinacijom gena (skup nekih vrijednosti), i traže optimalno rješenje, transformirajući pojedince populacije kroz umjetnu evoluciju među njima.
Odstupanja u jednom ili drugom smjeru pojedinih elemenata u općem slučaju su u skladu s uobičajenim zakonom raspodjele veličina. U isto vrijeme, GA osigurava nasljednost osobina, od kojih su najprilagodljivije fiksirane, čime se osigurava najbolja populacija.
Osnovni genetski algoritam
U koracima razgrađujemo najjednostavnije (klasične) GA.
- Inicijalizacija početnih vrijednosti, tj. Definicija primarne populacije, skup pojedinaca s kojima će se odvijati evolucija.
- Utvrđivanje primarne sposobnosti svakog pojedinca u populaciji.
- Provjerite uvjete raskida za ponavljanje algoritma.
- Korištenje funkcije odabira.
- Korištenje genetskih operatora.
- Stvaranje nove populacije.
- Koraci 2-6 ponavljaju se u ciklusu sve dok se ne ispuni potreban uvjet, nakon čega dolazi do odabira najprilagodljivije osobe.
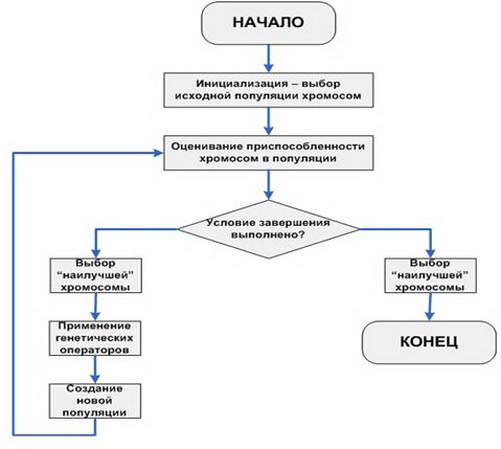
Idemo ukratko kroz male očite dijelove algoritma. Postoje dva uvjeta za raskid:
- Broj ponavljanja.
- Kvaliteta rješenja.
Genetski operatori su operator mutacije i skretnica. Mutacija mijenja slučajne gene s određenom vjerojatnošću. U pravilu, vjerojatnost mutacije ima nisku numeričku vrijednost. Razgovarajmo više o postupku genetskog algoritma "križanje". To se događa prema sljedećem načelu:
- Za svaki par roditelja koji sadrži L gene, točka prijelaza Tsk i je nasumično odabrana.
- Prvi potomak je sastavljen spajanjem [1; Tsk i ] geni prvog roditelja [Tsk i + 1 ; L] gena drugog roditelja.
- Drugi potomak je sastavljen obrnutim putem. Sada na gene drugog roditelja [1; Tsk i ] dodaje gene prvog roditelja u položaje [Tsk i + 1 ; L].
Neobičan primjer
Problem rješavamo genetskim algoritmom na primjeru traženja pojedinca s maksimalnim brojem jedinica. Neka se pojedinac sastoji od 10 gena. Primarnu populaciju dodjeljujemo u iznosu od osam pojedinaca. Očito, najbolji pojedinac bi trebao biti 1111111111. Nadoknadimo odluku GA.
- Inicijalizacija. Odaberite 8 slučajnih pojedinaca:
| n 1 | 1110010101 | n 5 | 0101000110 |
| n 2 | 1100111010 | n 6 | 0100110101 |
| n 3 | 1110011110 | n 7 | 0110111011 |
| n 4 | 1011000000 | n 8 | 0100001001 |
- Procjena sposobnosti. Očito, u našem genetskom algoritmu, funkcija fitnessa F će brojati broj jedinica u svakom pojedincu. Dakle, imamo:
| n i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| F (n i ) | 6 | 7 | 8 | 3 | 4 | 5 | 7 | 3 |
Iz tablice je vidljivo da pojedinci 3 i 7 imaju najveći broj jedinica, te su stoga najprikladniji članovi populacije za rješavanje problema. Budući da u ovom trenutku ne postoji rješenje tražene kvalitete, algoritam nastavlja s radom. Potrebno je izvršiti odabir pojedinaca. Radi lakšeg objašnjenja, neka je odabir slučajan, a dobivamo uzorak pojedinaca {n 7 , n 3 , n 1 , n 7 , n 3 , n 7 , n 4 , n 2 } - to su roditelji za novu populaciju.
- Korištenje genetskih operatora. Opet, za jednostavnost, pretpostavljamo da je vjerojatnost mutacija 0. Drugim riječima, svih 8 pojedinaca prolazi svoje gene kao što su. Za prijelaz pravimo parove pojedinaca nasumice: (n 2 , n 7 ), (n 1 , n 7 ), (n 3 , n 4 ) i (n 3 , n 7 ). Na isti slučajni način, odabrane su točke prijelaza za svaki par:
| par | (str. 2 , str. 7 ) | (n 1 , n 7 ) | (p 3 , p 4 ) | (str. 3 , str. 7 ) |
| roditelji | [1100111010] [0110111011] | [1110010101] [0110111011] | [1110011110] [1011000000] | [1110011110] [0110111011] |
| Tsk i | 3 | 5 | 2 | 8 |
| potomci | [1100111011] [0110111010] | [1110011011] [0110110101] | [1111000000] [1010011110] | [1110011111] [0110111010] |
- Kompilacija nove populacije koja se sastoji od potomaka:
| n 1 | 1100111011 | n 5 | 1111000000 |
| n 2 | 0110111010 | n 6 | 1010011110 |
| n 3 | 1110011011 | n 7 | 1110011111 |
| n 4 | 0110110101 | n 8 | 0110111010 |
- Procjenjujemo sposobnost svakog pojedinca nove populacije:
| n i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| F (n i ) | 7 | 6 | 7 | 6 | 4 | 6 | 8 | 6 |
Daljnje akcije su očite. Najzanimljivija stvar u GA jest, ako procijenimo prosječni broj jedinica u svakoj populaciji. U prvoj populaciji, u prosjeku, bilo je 5.375 jedinica za svakog pojedinca, u populaciji potomaka - 6.25 jedinica po pojedincu. A takva će se značajka promatrati čak i ako se tijekom mutacija i prelaska osobe s najvećim brojem jedinica u prvoj populaciji izgubi.
Plan provedbe
Stvaranje genetskog algoritma prilično je složen zadatak. Prvo, planiramo u obliku koraka, nakon čega ćemo ih detaljnije ispitati.
- Definicija reprezentacije (abeceda).
- Definicija operatora slučajne promjene.
- Definicija preživljavanja pojedinaca.
- Generacija primarne populacije.
Prva faza kaže da abeceda u kojoj će svi elementi skupa rješenja ili populacije biti kodirani mora biti dovoljno fleksibilna da omogući istodobno izvođenje potrebnih slučajnih permutacija i procjenu sposobnosti elemenata, primarnih i onih koji su prošli kroz promjene. Matematički je utvrđeno da je nemoguće stvoriti idealnu abecedu za ove svrhe, stoga je njezina kompilacija jedan od najtežih i najvažnijih koraka kako bi se osiguralo stabilno djelovanje GA.

Jednako je teško definirati izjave o promjenama i stvoriti potomke. Postoje mnogi operatori koji su u stanju izvršiti potrebne radnje. Na primjer, iz biologije je poznato da se svaka vrsta može reproducirati na dva načina: seksualno (križanjem) i aseksualnim (mutacijama). U prvom slučaju roditelji razmjenjuju genetski materijal, u drugom se događaju mutacije, koje određuju unutarnji mehanizmi tijela i vanjski utjecaji. Osim toga, mogu se koristiti modeli reprodukcije koji ne postoje u divljini. Primjerice, koristite gene tri ili više roditelja. Slično tome, ukrštanje mutacije u genetski algoritam može uključivati raznolik mehanizam.
Izbor metode preživljavanja može biti izuzetno varljiv. Postoji mnogo načina u genetskom algoritmu za uzgoj. I, kao što praksa pokazuje, pravilo "opstanka najjačih" nije uvijek najbolje. Pri rješavanju složenih tehničkih problema često se ispostavlja da najbolje rješenje dolazi iz mnoštva srednjih ili još goreg. Stoga se često prihvaća probabilistički pristup, koji kaže da najbolje rješenje ima veće šanse za preživljavanje.

Posljednja faza pruža fleksibilnost algoritma, što nitko drugi nema. Početna populacija rješenja može se definirati bilo na temelju bilo kojih poznatih podataka, ili na potpuno slučajan način, jednostavnim preraspodjelom gena unutar pojedinaca i stvaranjem slučajnih pojedinaca. Međutim, uvijek je vrijedno zapamtiti da učinkovitost algoritma ovisi o početnoj populaciji.
efikasnost
Učinkovitost genetskog algoritma u cijelosti ovisi o ispravnosti koraka opisanih u planu. Osobito utjecajan predmet ovdje je stvaranje primarne populacije. Za to postoji mnogo pristupa. Opisujemo nekoliko:
- Stvaranje cjelovite populacije koja će uključivati sve vrste opcija za pojedince u određenom području.
- Slučajno stvaranje pojedinaca na temelju svih važećih vrijednosti.
- Dot slučajno kreiranje pojedinaca, kada je među prihvatljivim vrijednostima odabran raspon generacije.
- Kombinirajući prva tri načina stvaranja populacije.

Dakle, možemo zaključiti da učinkovitost genetskih algoritama uvelike ovisi o iskustvu programera u ovom pitanju. To je i nedostatak genetskih algoritama i njihova prednost.