Unicode tablica slobodnih znakova
Unicode je međunarodni standard za kodiranje znakova koji vam omogućuje da na svim računalima na svijetu jednako prikazujete tekstove, bez obzira na jezik sustava koji se na njemu koristi.
Osnove
Da bismo razumjeli zašto je potrebna tablica Unicode simbola, najprije pogledajmo mehanizam za prikaz teksta na zaslonu monitora. Računalo, kao što znamo, obrađuje sve informacije u digitalnom obliku i mora biti prikazano u grafičkom obliku za ispravnu percepciju osobe. Stoga, da bismo mogli pročitati ovaj tekst, moramo riješiti najmanje dva problema:
- Kodiranje znakova za ispis u digitalnom obliku.
- Osigurati operativni sustav s mogućnošću usklađivanja digitalnog oblika s vektorskim simbolima, drugim riječima, pronaći ispravna slova.
Prva kodiranja
Predak svih kodiranja smatra se američkim ASCII. Opisao je latinicu koja se koristi na engleskom jeziku znakove interpunkcije i Arapski brojevi. Upravo je 128 znakova u njemu postalo temelj daljnjeg razvoja - čak ih i moderna tablica Unicode simbola koristi. Slova slova latinske abecede zauzela su prvo mjesto u bilo kojem kodiranju.

Sveukupno, ASCII je dopuštao spremanje 256 znakova, ali budući da je prvih 128 bilo latiničnim znakovima, preostalih 128 se počelo koristiti diljem svijeta za stvaranje nacionalnih standarda. Na primjer, u Rusiji su CP866 i KOI8-R stvoreni na njegovoj osnovi. Takve varijacije nazivane su proširene verzije ASCII-a.
Kodne stranice i napuknuća
Daljnji razvoj tehnologije i pojava GUI dovela je do toga da je Američki institut za standardizaciju kreirao kodiranje ANSI. Za ruske korisnike, posebno s iskustvom, njegova je verzija poznata pod nazivom Windows 1251. Po prvi put u njoj je korišten koncept "kodna stranica". Uz pomoć kodnih stranica koje su sadržavale simbole nacionalnih pisama, osim latinskog, uspostavljeno je "međusobno razumijevanje" između računala koja se koriste u različitim zemljama.
Međutim, prisutnost velikog broja različitih kodiranja korištenih za jedan jezik počela je uzrokovati probleme. Bilo je takozvanih krakozabrija. Oni su nastali zbog neusklađenosti izvorne kodne stranice, na kojoj su stvorene bilo kakve informacije, i kodne stranice koja se prema zadanim postavkama koristi na računalu krajnjeg korisnika.

Primjerice, mogu se navesti gore navedene kodiranja CP866 i KOI8-R. Pisma u njima razlikovala su se kodnim pozicijama i načelima smještaja. U prvom su raspoređeni po abecednom redu, au drugom - proizvoljno. Možete zamisliti što se događalo pred očima korisnika koji je pokušao otvoriti takav tekst bez potrebne kodne stranice ili ako je računalo pogrešno protumačilo.
Stvorite Unicode
Širenje Interneta i srodnih tehnologija, kao što je e-pošta, dovelo je do toga da je na kraju situacija s iskrivljavanjem tekstova prestala odgovarati svima. Vodeće IT tvrtke osnovale su konzorcij Unicode ("Unicode Consortium"). Tablica znakova, koja im je predstavljena 1991. pod imenom UTF-32, dopuštala je pohranjivanje više od milijardu jedinstvenih znakova. To je bio najvažniji korak na putu dešifriranja tekstova.

Međutim, prva univerzalna tablica Unicode UTF-32 kodova znakova nije bila široko korištena. Glavni razlog bio je višak pohranjenih podataka. To je brzo izračunati da za zemlje u kojima latinica kodiran pomoću nove univerzalne tablice, tekst će zauzimati četiri puta više prostora nego kada se koristi proširena ASCII tablica.
Unicode razvoj
Sljedeći Unicode UTF-16 tablica simbola popravila je ovaj problem. Kodiranje je provedeno na pola broja bitova, ali se istovremeno smanjio broj mogućih kombinacija. Umjesto milijardi znakova, omogućuje vam uštedu samo 65.536, ali je bila toliko uspješna da je taj broj, prema odluci Konzorcija, određen kao osnovni prostor za pohranu znaka Unicode standarda.
Unatoč tom uspjehu, UTF-16 nije odgovarao svima, budući da je količina pohranjenih i prenesenih informacija još uvijek bila dvostruko veća. Univerzalno rješenje bilo je UTF-8, Unicode tablica s promjenjivom duljinom. To se može nazvati proboj na ovom području.

Dakle, uvođenjem posljednja dva standarda, tablica Unicode simbola riješila je problem jedinstvenog prostora koda za sve trenutno korištene fontove.
Unicode za ruski jezik
Zbog varijabilne duljine koda koji se koristi za prikaz znakova, latinski se kodira u Unicode na isti način kao u ASCII-ovom preteči, tj. U jednom bitu. Za druge alfabete slika može izgledati drugačije. Na primjer, znakovi gruzijske abecede koriste se za kodiranje tri bajta, a znakovi ćiriličnog pisma - dva. Sve je to moguće u okviru korištenja Unicode UTF-8 standarda (tablica simbola). Ruski jezik ili ćirilično pismo zauzima 448 mjesta u općem prostoru koda podijeljenom u pet blokova.
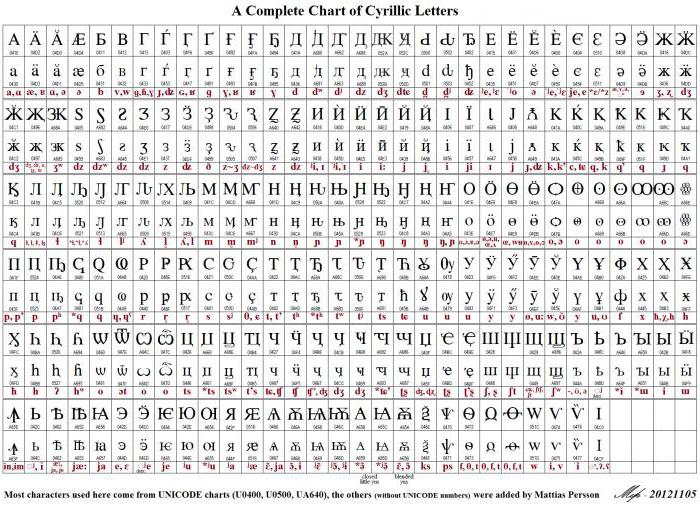
Ovih pet blokova obuhvaćaju glavnu ćiriličnu i crkvenoslavensku abecedu, kao i dodatna slova drugih jezika koji se koriste ćirilicom. Broj pozicija se dodjeljuje za prikaz starih oblika prikazivanja ćiriličnih slova, dok 22 mjesta od ukupnog broja ostaju slobodna.
Trenutna verzija Unicode-a
Rješenjem svoje primarne zadaće, a to je standardizacija fontova i stvaranje jedinstvenog prostora za njih, Konzorcij nije zaustavio svoj rad. Unicode se stalno razvija i raste. Najnovija trenutna verzija ovog standarda, 9.0, objavljena je 2016. godine. Uključio je šest dodatnih abecedi i proširio popis standardiziranih emotikona.
Treba napomenuti da, kako bi se pojednostavilo istraživanje, čak i tzv mrtvi jezici. Ime su dobili zato što nema ljudi za koje bi to bili rođaci. Ova skupina uključuje i jezike koji su se svodili na naše vrijeme samo u obliku pisanih spomenika.
U principu, svatko se može prijaviti za dodavanje znakova u novu Unicode specifikaciju. Istina, to će morati ispuniti pristojnu količinu izvornih dokumenata i potrošiti puno vremena. Živi primjer toga je priča o programeru Terenceu Edenu. Godine 2013. podnio je zahtjev za uključivanje u specifikaciju znakova vezanih za označavanje gumba za kontrolu snage računala. U tehničkoj dokumentaciji korišteni su od sredine 70-ih godina prošlog stoljeća, ali dok se ne pojavi specifikacija 9.0, oni nisu bili dio Unicode-a.
Tablica simbola
Na svakom računalu, bez obzira na korišteni operacijski sustav, koristi se tablica Unicode simbola. Kako koristiti ove tablice, gdje ih pronaći i zašto mogu biti korisne prosječnom korisniku?
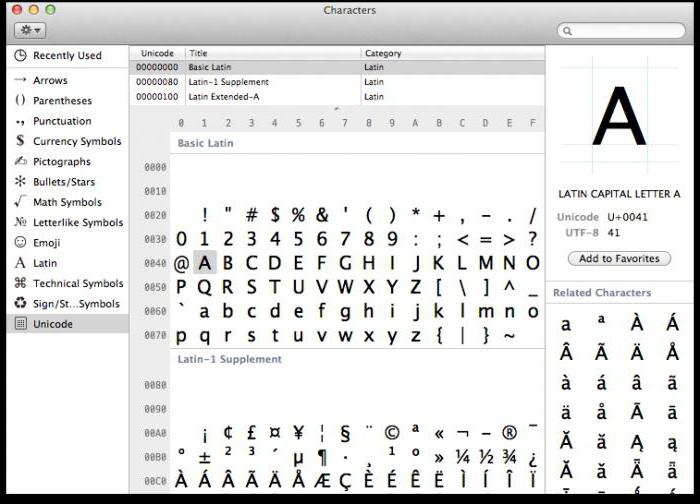
U sustavu Windows tablica simbola nalazi se u izborniku "Alati". U obitelji Linux operacijskih sustava, obično se može naći u pododjeljku "Standard", te u MacOS-u u postavkama tipkovnice. Glavna svrha ove tablice je unos znakova u tekstualne dokumente koji se ne nalaze na tipkovnici.
Aplikacija za takve tablice može se naći najširi: od unosa tehničkih simbola i ikona nacionalnih monetarnih sustava do pisanja uputa za praktičnu primjenu Tarot karata.
U zaključku
Unicode se koristi svugdje i ulazi u naše živote zajedno s razvojem Interneta i mobilnih tehnologija. Zahvaljujući njegovom korištenju, sustav međuetničkih komunikacija znatno je pojednostavljen. Možemo reći da je uvođenje Unicoda indikativno, ali potpuno neprimetno iz primjera korištenja tehnologije za opće dobro cijelog čovječanstva.