ASCII kodiranje. ASCII tablica kodiranja
ispod informacije o kodiranju u računalu se podrazumijeva proces njegovog pretvaranja u oblik, što omogućuje organiziranje prikladnijeg prijenosa, pohranjivanja ili automatske obrade tih podataka. U tu svrhu koriste se različite tablice. ASCII kodiranje je prvi sustav razvijen u Sjedinjenim Državama za rad s tekstom na engleskom jeziku, koji je naknadno distribuiran u cijelom svijetu. Opis, svojstva, svojstva i daljnja upotreba članka prikazani su u nastavku.
Prikaz i pohranjivanje podataka u računalu
Simboli na računalnom monitoru ili mobilnom digitalnom gadgetu formiraju se na temelju skupova vektorskih oblika različitih znakova i koda, koji omogućuju da se među njima pronađe lik koji treba umetnuti na pravo mjesto. To je niz bitova. Dakle, svaki simbol mora jednoznačno odgovarati skupu nula i onih koji stoje u određenom, jedinstvenom poretku.
Kako je sve počelo
Povijesno gledano, prva računala su bila engleski. Za kodiranje simboličkih informacija u njih bilo je dovoljno koristiti samo 7 bitova memorije, dok je za tu svrhu dodijeljen 1 bajt koji se sastoji od 8 bita. Broj znakova koje je računalo razumjelo u ovom slučaju bilo je 128. Ovi su znakovi uključivali englesku abecedu sa svojim znakovima interpunkcije, brojevima, a neke posebnih znakova. Engleski 7-bitni kod s odgovarajućom tablicom (kodnom stranicom), razvijenom 1963. godine, nazvan je American Standard Code za razmjenu informacija. Obično je za njegovu oznaku korištena kratica “ASCII Coding” i još se koristi.
Prijelaz na višejezičnost
Tijekom vremena, računala su se počela široko primjenjivati u zemljama koje ne govore engleski. U tom smislu, postoji potreba za kodiranjem koje dopušta uporabu nacionalnih jezika. Odlučeno je da se ne iznova pronalazi kotač i ASCII kao osnova. Tablica kodiranja u novom izdanju značajno se proširila. Korištenje 8. bita dopušteno je prevesti 256 znakova u računalni jezik.
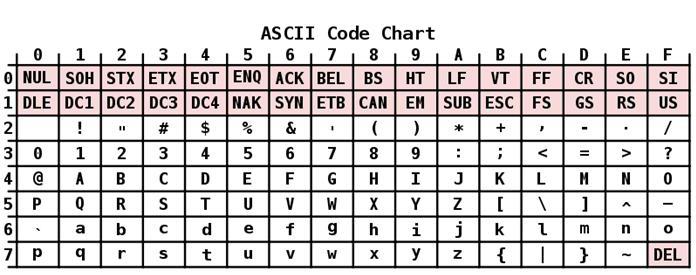
opis
ASCII kodiranje ima tablicu koja je podijeljena u 2 dijela. Smatra se da je općeprihvaćeni međunarodni standard tek njegova prva polovica. Uključuje:
- Znakovi s rednim brojevima od 0 do 31, kodirani sekvencama od 00000000 do 00011111. Oni su rezervirani za kontrolne znakove koji kontroliraju proces prikazivanja teksta na zaslonu ili pisaču, zvučnim signalom itd.
- Znakovi s NN u tablici od 32 do 127, kodirani sekvencama od 00100000 do 01111111 čine standardni dio tablice. To uključuje razmak (N 32), latinična slova (mala i velika slova), deset-znamenkasti broj od 0 do 9, interpunkcijske znakove, zagrade različite vrste i druge znakove.
- Likovi s rednim brojevima od 128 do 255, kodirani sekvencama od 10.000.000 do 1.000 To uključuje slova nacionalnih pisama osim latinice. Ovaj alternativni dio tablice je ASCII kodiranje koje se koristi za pretvaranje ruskih znakova u računalni oblik.
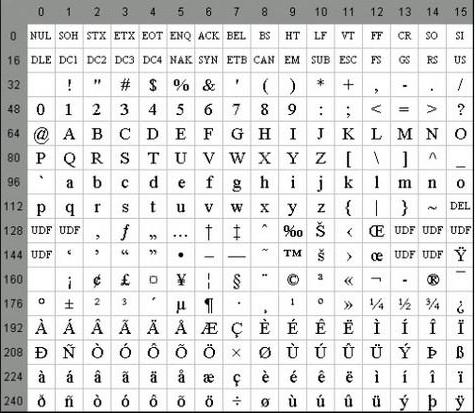
Neka svojstva
Posebne značajke ASCII kodiranja su razlika između slova "A" - "Z" donjeg i gornjeg registra sa samo jednim bitom. Ova okolnost uvelike pojednostavljuje konverziju registra, kao i njegovu provjeru pripadnosti određenom rasponu vrijednosti. Osim toga, sva slova u ASCII sustavu kodiranja prikazana su vlastitim serijskim brojevima u abecedi, koji su u binarnom brojevnom sustavu zapisani u 5 znamenki, a za mala slova 011, a gornji 010 2 .
Među značajkama kodiranja ASCII se može izbrojati i prikazati 10 znamenki - "0" - "9". U drugom brojevnom sustavu, počinju s 00112, a završavaju s 2 broja. Dakle, 0101 2 je ekvivalent decimalnom broju od pet, tako da se znak "5" piše kao 0011 01012. Na temelju gore navedenog, možete jednostavno pretvoriti binarno-decimalne brojeve u niz u ASCII dodavanjem slijeda bita 00112 svakom grickanju lijevo.

"Unicode"
Kao što znate, za prikazivanje tekstova na jezicima skupine jugoistočne Azije potrebna su tisuća znakova. Takav broj njih nije ni na koji način opisan u jednom bajtu informacija, pa čak i proširene verzije ASCII-a više nisu mogle zadovoljiti rastuće potrebe korisnika iz različitih zemalja.
Tako je postalo nužno stvoriti univerzalno kodiranje teksta, čiji je razvoj, u suradnji s mnogim liderima globalne IT industrije, preuzet od strane Unicode konzorcija. Njegovi stručnjaci kreirali su sustav UTF 32. U njega je dodijeljeno 32 bita za kodiranje 1 znaka, koji čine 4 bajta informacija. Glavni nedostatak bio je oštar porast količine potrebne memorije za čak 4 puta, što je uzrokovalo mnoge probleme.
Istodobno, za većinu zemalja s službenim jezicima koji pripadaju indoeuropskoj grupi, broj znakova jednak je 2 32 više nego suvišan.
Kao rezultat daljnjeg rada stručnjaka iz Unicode konzorcija, pojavio se UTF-16 kodiranje. To je postala mogućnost pretvaranja simboličkih informacija, koje su uređivale svakoga kako u smislu količine potrebne memorije tako iu smislu broja kodiranih znakova. Zato je UTF-16 prihvaćen po defaultu i zahtijeva 2 bajta da budu rezervirani za jedan znak.
Čak i ova prilično napredna i uspješna verzija Unicode-a imala je neke nedostatke, a nakon prebacivanja s proširene verzije ASCII-a na UTF-16 udvostručila je težinu dokumenta.
U tom smislu, odlučeno je da se koristi kodiranje s varijabilnom duljinom UTF-8. U tom slučaju, svaki znak u izvornom tekstu kodiran je u nizu od 1 do 6 bajtova.

Obratite se američkom standardnom kodu za razmjenu informacija
Svi znakovi latinica u UTF-8 varijabilnoj duljini kodiranoj u 1 bajt, kao u ASCII sustavu kodiranja.
Posebna značajka UTF-8 je da u slučaju teksta na latinskom bez upotrebe drugih znakova, čak i programi koji ne razumiju Unicode i dalje dopuštaju čitanje. Drugim riječima, osnovni dio ASCII kodiranja teksta jednostavno se prenosi na novu UTF varijabilnu duljinu. Ćirilični znakovi u UTF-8 zauzimaju 2 bajta, a primjerice gruzijski - 3 bajta. Stvaranjem UTF-16 i 8 riješen je glavni problem stvaranja jedinstvenog prostora koda u fontovima. Od tada, proizvođači fontova trebaju samo ispuniti tablicu s vektorskim oblicima tekstualnih simbola na temelju njihovih potreba.
U različitim operacijskim sustavima prednost se daje različitim kodiranjima. Da bi mogli čitati i uređivati tekstove upisane u nekom drugom kodiranju, koriste se ruski programi za pretvorbu teksta. Neki tekstualni uređivači sadrže ugrađene transkodere i omogućuju čitanje teksta bez obzira na kodiranje.

Sada znate koliko je znakova u ASCII i kako i zašto je razvijeno. Naravno, danas je Unicode standard postao najrasprostranjeniji u svijetu. Međutim, ne smijemo zaboraviti da je stvoren na temelju ASCII-a, pa biste trebali cijeniti doprinos svojih razvojnih inženjera u području IT-a.